letBulochkin.github.io
Ceph: краткое введение
2020-08-26
Объектное хранилище
Объект - это набор из некоторых данных, характеризующих их метаданных и уникального идентификатора объекта. “Некоторыми данными” может быть как файл в традиционном понимании, так и любой набор битов. Метаданными являются пары ключ-значение, характеризующие объект. В Ceph состав метаданных не регламентируется и определяется не ядром Ceph, а его подсистемами, обеспечивающими доступ к объектам (например, CephFS). Идентификатор объекта в Ceph уникален для всего кластера. В отличии от файловых, объектные хранилища линейны, то есть не имеют древовидной структуры из каталогов и подкаталогов - все объекты хранятся на одном иерархическом уровне. Объект в объектном хранилище однозначно позиционируется благодаря идентификатору, файл в файловом - благодаря абсолютному или относительному пути.
При этом в объектном хранилище можно имитировать древовидную структуру каталогов, если задавать объектам одинаковый набор префиксов, например:
top-level-object
catalog/object1
catalog/subcatalog/object1
catalog/subcatalog/object2
В примере выше все объекты фактически находятся на одном иерархическом уровне, однако благодаря использованию префиксов catalog/ и subcatalog/ создается имитация дерева каталогов (УТОЧНИТЬ).
Подсистемы Ceph
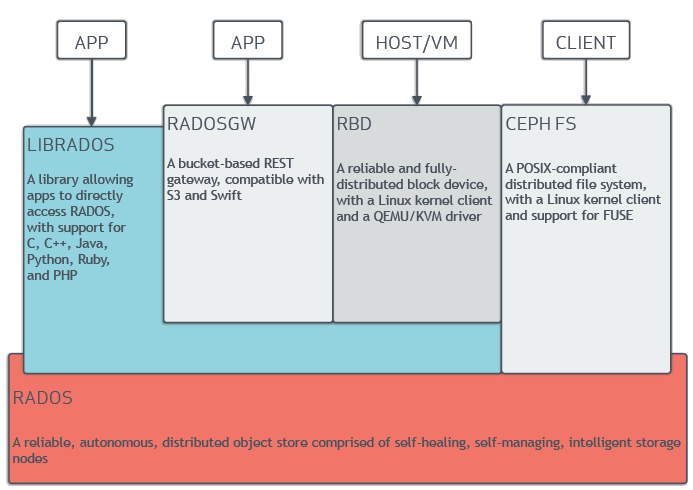
Базовым элементом Ceph является RADOS - Reliable Autonomic Distributed Object Store, Надежное Автономное Распределенное Объектное Хранилище. RADOS обеспечивает сохранность и согласованность объектов в хранилище, а также предоставляет универсальный интерфейс для подсистем более высокого уровня - librados API. Посредством данного интерфейса с RADOS взаимодействуют подсистемы, обеспечивающие доступ к хранилищу:
- как к блочному устойству - RBD, RADOS Block Device;
- как к файловой системе - CephFS;
- как к объектному хранилищу через RESTful S3-совместимое API - RGW, RADOS Gateway.
Компоненты и структура хранения
Структуру хранения в Ceph можно разделить на логический и физический уровень. Она состоит из трех основных элементов иерархии - пула, группы размещения (PG) и устройства хранения (OSD).
На логическом уровне данные в Ceph хранятся в пулах. Пул является наивысшей точкой организации хранения объектов. Для объектов в пуле задается глобальный фактор репликации - количество копий (реплик) объекта (параметр size), которое необходимо хранить независимо друг от друга на OSD (см. ниже) в разных доменах отказа (см. ниже), а также минимальное возможное число реплик объектов в пуле (параметр min_size). Различные значения этих параметров могут приводить к различному поведению. При size=3 и min_size=2 объект будет записан на три OSD, а подтверждение об успешной записи будет отправлено при записи уже на две OSD. С другой стороны, операции над объектами будут возможны, пока хотя бы две из трех реплик доступны, но как только станет доступна лишь одна реплика, все операции будут заморожены до восстановления доступа к хотя бы еще одной реплике.
Следующей ступенью в структуре хранения Ceph являются группы размещения (placement groups, PG). Группы размещения являются связующим звеном между логическим и физическим уровнем хранилища. На логическом уровне каждый объект хранится в строго определенной PG. На физическом уровне каждый объект в PG хранится в виде реплик на нескольких устройствах хранения (Object Storage Device, OSD - устройство объектного хранилища) - на стольких, сколько указано в факторе репликации size. При этом среди доступных OSD выделяются первичная, вторичная и т.д. OSD могут входить в состав нескольких PG, при этом в одних PG устройство может быть первичным, а в других - вторичным; но в каждой PG есть только одна первичная OSD.
Финальным элементом в структуре хранения Ceph является устройство хранения OSD и связанный с ним OSD-демон. Обычно таким устройством является диск, но также может быть и RAID-массив, ISCSI-устройство. Как было сказано выше, в рамках одной PG одна OSD назначается первичной, а остальные OSD в количестве size-1 - вторичными, третичными и т.д. При выполнении операций чтения и записи клиенты обращаются непосредственно к первичной OSD. При первоначальной записи объекта подтверждение об окончании операции будет отправлено при записи на min_size OSD в PG. В рамках одной PG между входящими в нее OSD проводится одноранговый обмен (пиринг, peering) с целью поддержания в актуальном состоянии всех реплик данных. В случае потери первичной OSD ее замещает вторичная (третичная становится вторичной и т.д.), а в PG вводится еще одна OSD, на которую реплицируются данные. PG считается “живой”, пока доступно и активно min_size OSD.


OSD также не монолитна. Она состоит из журнала и непосредственно места для хранения данных. Журнал выполняет роль буфера - при операции записи данные помещаются сначала в журнал, а уже затем переносятся в место основного хранения. Распространена практика, при которой журнал OSD переносится на более быстродейственный тип устройства хранения, например, на SSD, что позволяет ускорить завершение операции записи.
Алгоритм CRUSH, карта CRUSH, наборы правил и демон MON
Алгоритм CRUSH (Controlled Replication Under Scalable Hashing, вариант перевода - Алгоритм Управляемых, Масштабируемым Хешированием Репликаций) является основным связующим звеном Ceph, позволяющим однозначно определить, какой объект будет храниться в какой PG, какие OSD входят в PG, какая OSD является для нее первичной и т.д. Алгоритм дает возможность клиентам при обращении к хранилищу моментально выяснить, в какой PG хранится нужный объект и обращаться непосредственно к OSD данной PG. Использование унифицированного алгоритма, всегда возвращающего конкретный результат для одних и тех же входных данных, вместо некоего управляющего брокера позволяет Ceph избавиться от потенциальной точки отказа.
Алгоритм можно представить в виде абстрактной хеш-функции, вычисляющей идентификатор PG для набора данных. Для управления размещением данных алгоритм использует т.н. карты CRUSH - виртуальную иерархию элементов кластера. Данную иерархию можно настроить самостоятельно, например, разбив хранилище на датацентры, затем на ряды, стойки, и, наконец, сами PG. Всё это разбиение будет отражено в карте CRUSH. В данной иерархии можно выделить домены отказа для различных пулов - например, если сделать доменом отказа датацентр, то реплики объектов PG данного пула будут распределены по OSD в разных датацентрах, стойку - в разных стойках. Эти домены отказа регулируются с помощью правил пулов.
Хранение карт CRUSH, их акутализацию и мониторинг состояния кластера осуществляет еще один важный компонент Ceph - демон монитора (MON). Один монитор и одна OSD - минимальный набор, при котором можно создать кластер Ceph. В целом одного монитора достаточно для поддержания работы кластера любого размера, однако отказ или недоступность MON в таком случае приведет к мгновенной остановке кластера. Поэтому для повышения отказоустойчивости вводятся несколько MON (обычно - нечетное количество), которые работают в кворуме. Кластер будет работоспособен, пока доступны больше половины мониторов.